A high fidelity sensor suite and the most complete HD maps of any public autonomous driving dataset.
KITScenes Multimodal is a European urban autonomous driving dataset targeting Level 4 robotaxi requirements, recorded across three cities by the Institute of Measurement and Control Systems (MRT) at Karlsruhe Institute of Technology (KIT). The dataset is built around a high-fidelity sensor suite: nine high-resolution global-shutter cameras provide full 360° surround coverage at 72.5 Mpx per frame, enabling novel view synthesis and holistic HD map perception, while seven highly dense long-range LiDARs with an effective range beyond 400 m push the limits of what current perception methods can achieve.
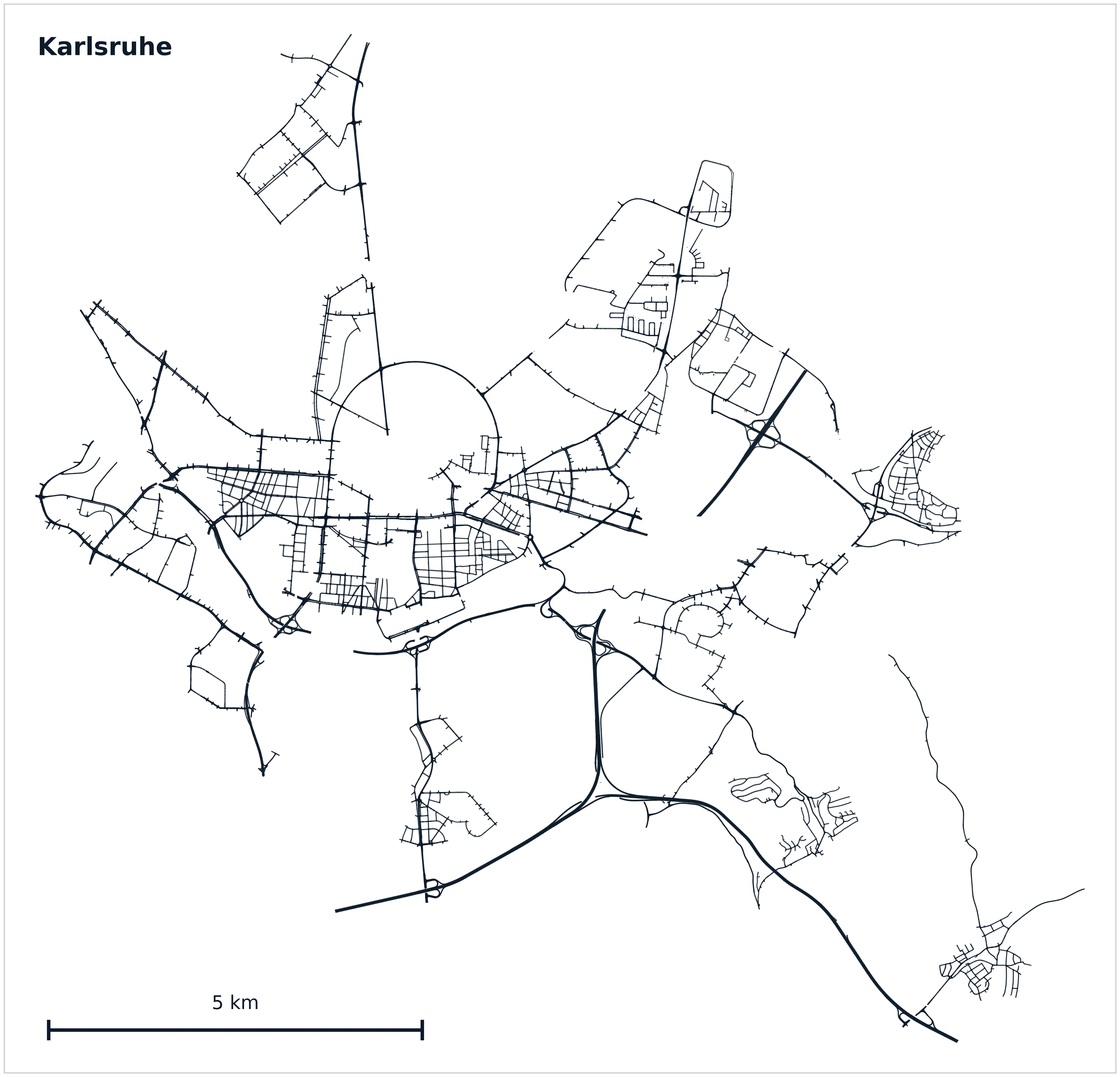
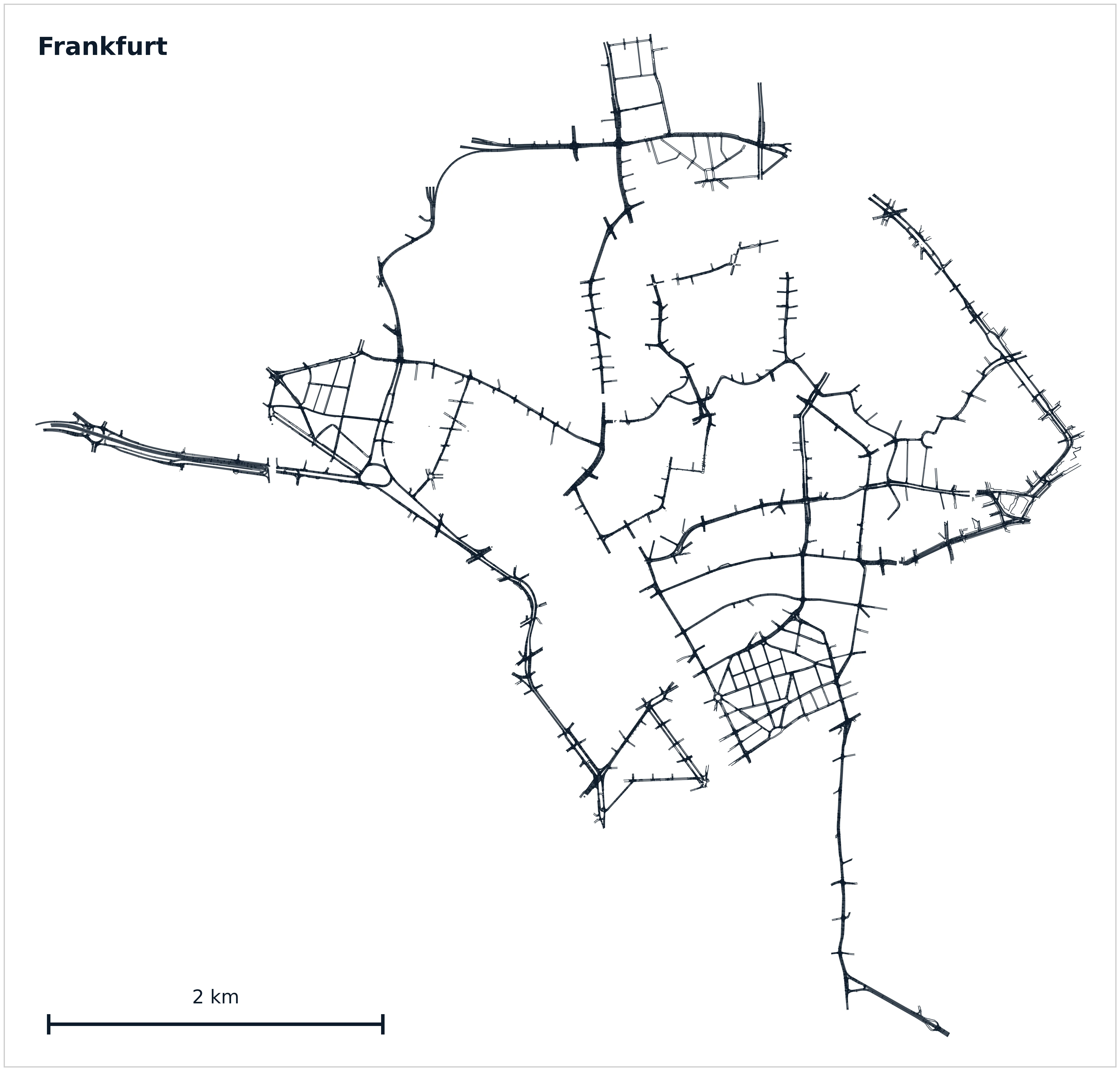
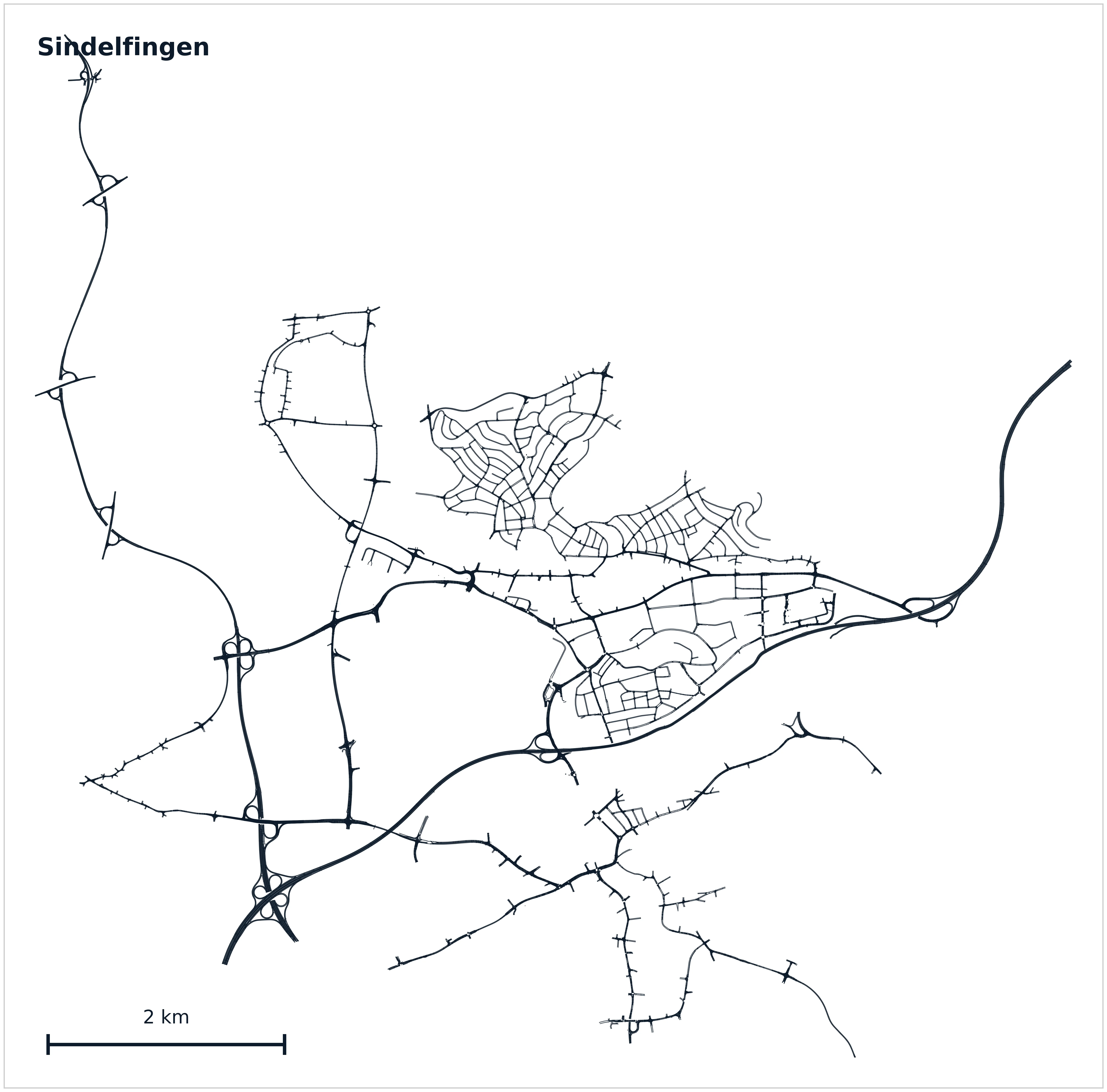
KITScenes Multimodal provides what we believe to be the most complete HD maps of any public autonomous driving dataset, annotated in Lanelet2 format across 62 km² with full topological connectivity between lanes, signs, and traffic lights. The maps have been validated in closed-loop autonomous driving trials using the open-source Autoware stack — meaning they are ready to drive on directly, while simultaneously enabling research to close the gap between the current state of the art and the actual requirements of L4 robotaxi deployment.
KITScenes Multimodal is released under CC BY-NC 4.0. An early preview is available on HuggingFace; the dataset is not yet recommended for final benchmark reporting.
Files, annotations, splits, and documentation may change. Not recommended for final benchmark reporting in this form.
Each frame combines surround cameras, dense LiDAR point clouds, and production-grade HD maps.


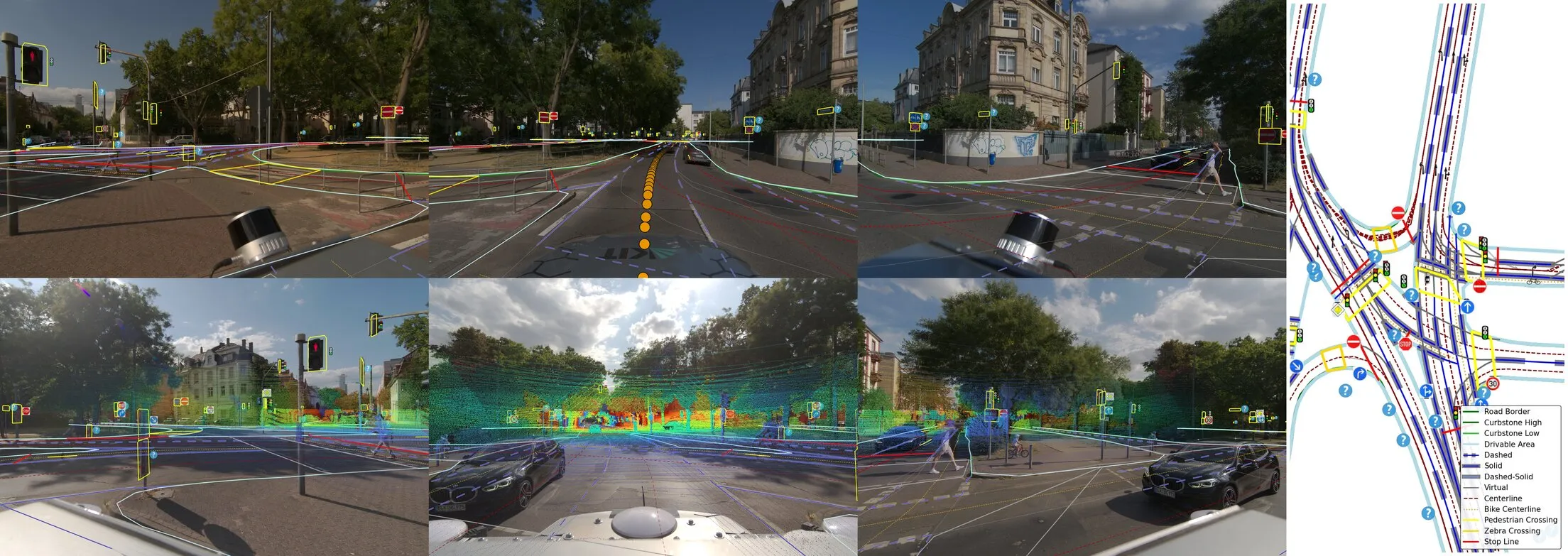
With 2.5× the total image resolution, 3× average LiDAR point density and nearly 2× maximum range, we raise the benchmark for publicly available sensor data.

Joy, a BMW 7-series with sensor rack

KITScenes Multimodal sets a new state of the art for temporally consistent high-resolution high-fidelity RGB surround vision, highly dense long-range lidar, and ranging modality coverage. We triple the average lidar point density and almost double the typical maximum range.
| Cameras | Radar | Lidar | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Cam | Stereo | MPix | FOV | Shutter | Cam sync | Comp. | Config | # | Avg pts | Max pts | Max range |
| nuScenes | 6 | — | 8.4 | 360° | Rolling | to lidar | JPEG | 5×3D | 1 | 34.7 k | 34.8 k | 102.1 m |
| ONCE | 7 | — | 14.5 | 360° | Rolling | to lidar | JPEG | — | 1 | 64.7 k | 69.7 k | 196.8 m |
| nuPlan Sensors | 8 | — | 19.2 | 360° | Rolling | to lidar | JPEG | — | 5 | 93.0 k | 100.3 k | 215.5 m |
| Argoverse 2 Sensor | 7 | 1 | 28.6 | 360° | Rolling | to lidar | JPEG | — | 2 | 96.9 k | 106.3 k | 217.4 m |
| WOD Perception | 5 | — | 10.4 | 230° | Rolling | to lidar | JPEG | — | 5 | 175.5 k | 215.9 k | 75.0 m |
| MAN TruckScenes | 4 | — | 9.3 | 360° | Rolling | to lidar | JPEG | 6×4D | 6 | 231.7 k | 296.7 k | 221.6 m |
| Zenseact Open | 1 | — | 8.3 | 120° | Rolling | — | PNG | — | 3 | 253.7 k | 311.1 k | 244.0 m |
| Nvidia PhysicalAI AV | 7 | — | 14.5 | 360° | Rolling | no | H.264 | 9×4D | 1 | 297.2 k | 344.1 k | 206.0 m |
| KITScenes Multimodal | 7 | 1 | 72.5 | 360° | Global | all cameras | JPEGLI | 3×4D | 7 | 906.4 k | 1,235.2 k | 409.2 m |
Cam = monocular cameras; Stereo = stereo camera pair; MPix = total resolution per frame; Comp. = image compression.
We provide full and open details about all sensors used to collect KITScenes Multimodal.
All cameras are manufactured by Lucid Vision Labs and use low-distortion Fujinon CF8ZA-1S-23M lenses with 23 MPix maximum resolution.
| Surround | Stereo (tilted) | Hi-Res / Long-range | |
|---|---|---|---|
| Count | 6 | 1 pair | 1 |
| Camera | ATL071S-CC | ATL071S-CC + ATL071S-MC | ATP162S-CC |
| Sensor | Sony IMX420, 1.1″ | Sony IMX420, 1.1″ | Sony IMX542, 1.1″ |
| Resolution | 3200×2200 (7.1 MPix) | 3200×2200 (7.1 MPix) | 5320×3032 (16.2 MPix) |
| Pixel pitch | 4.5 µm | 4.5 µm | 4.5 µm |
| FOV (H×V) | 87.1°×63.3° | 63.3°×86.9° | 88.4°×54.4° |
| Top (–Dec. 2025) | Top (Jan. 2026–) | Corner (tilted) | Automotive | |
|---|---|---|---|---|
| Count | 1 | 1 | 2 | 4 |
| Model | Velodyne VLS128-AP | Hesai OT128 | Hesai XT32 | Seyond Falcon K1 |
| Channels | 128 | 128 | 32 | 150 lines |
| FOV (H×V) | 360°×40° | 360°×40° | 270°×31° | 120°×25° |
| Resolution (H×V) | 0.2°×0.1° | 0.1°×0.125° | 0.18°×1.3° | 0.18°×0.24° |
| Range (max) | 245 m | 230 m | 120 m | 500 m |
| Range @ 10% refl. | 245 m | 200 m | 80 m | 250 m |
| Wavelength | 905 nm | 905 nm | 905 nm | 1550 nm |
| Effective pts/s | 2.19 M | 6.91 M | 864 k | 900 k |
| Returns | strongest | last + strongest | last + strongest | strongest |
The top lidar was improved in December 2025. FoV and effective points of corner lidars are intentionally limited.
| Long-range (×3) | |
|---|---|
| Model | Continental ARS548 RDI |
| Frequency band | 76–77 GHz |
| FOV (H×V) | 120°×28° |
| Beam width (3 dB, H×V) | 1.2°×2.3° |
| Angular accuracy (H×V) | ±0.1°×±0.1° |
| Range (max) | 300 m |
| Range resolution | 0.22 m |
| Velocity range | −400 to +200 km/h |
| Output | 4D detections + RCS |
| GNSS | GNSS/INS | |
|---|---|---|
| Model | Septentrio mosaic-X5 | Septentrio AsteRx SBi3 Pro+ |
| Antennas | 1 | 2 |
| Hardware channels | 448 | 544 |
| RTK accuracy (H / V) | 0.6 cm / 1.0 cm | 0.6 cm / 1.0 cm |
| Standalone acc. (H / V) | 1.2 m / 1.9 m | 1.2 m / 1.9 m |
| Heading accuracy (RTK) | — | 0.2° |
| Pitch/roll acc. (RTK) | — | 0.02° |
| Velocity accuracy | 3 cm/s | 2 cm/s (RTK) |
| Position update rate | 100 Hz | 10 Hz (integrated) |
| Integrated IMU | — | ADIS16500 |
To our knowledge, no prior dataset provides HD maps that are simultaneously reprojection-accurate in 3D, complete in regulatory structure, and validated in an open-source planning stack.
HD map and sensor-suite features across public autonomous driving datasets. ✓ yes ◑ partial ✗ no ( ) unreleased
| Dataset | Area (km²) | Region | All sensors | 360° cam | 3D lanes | Lane border type | Bike lanes | 3D traffic elements | Full topology | Human HD map | OSS AD stack |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Limited spatial learning | |||||||||||
| WOD Perception | 76 | US | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ |
| nuPlan Sensors † | ↑ | US, Asia | ✓ | ✓ | ✗ | ◑ | ✗ | ✗ | ◑ | ✓ | ✗ |
| AV2 TbV | 42 | US | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ |
| Nvidia PhysicalAI AV | ↑↑↑ | US, EU | ✓ | ✓ | (✓) | (✗) | (✗) | (✓) | (✗) | (✗) | ✗ |
| Full spatial learning | |||||||||||
| nuScenes | 5 | US, Asia | ✓ | ✓ | ✗ | ◑ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Argoverse 2 Sensor | 17 | US | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ |
| OpenLane-V2 † | 22 | US, Asia | ✗ | ✓ | ◑ | ◑ | ✗ | ✗ | ◑ | ✓ | ✗ |
| KITScenes Multimodal | 62 | EU | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
† nuPlan Sensors: shorthand for the ~10% of scenes with available sensor data; traffic-light states via offline estimation, no sensor linkage. OpenLane-V2: built on AV2 and nuScenes; limited 2D bounding-box traffic elements within 25×50 m at 2 Hz. Nvidia PhysicalAI AV: entries in parentheses reflect planned but unreleased data, not verified. ↑ = large coverage based on dataset description; exact area not reported.
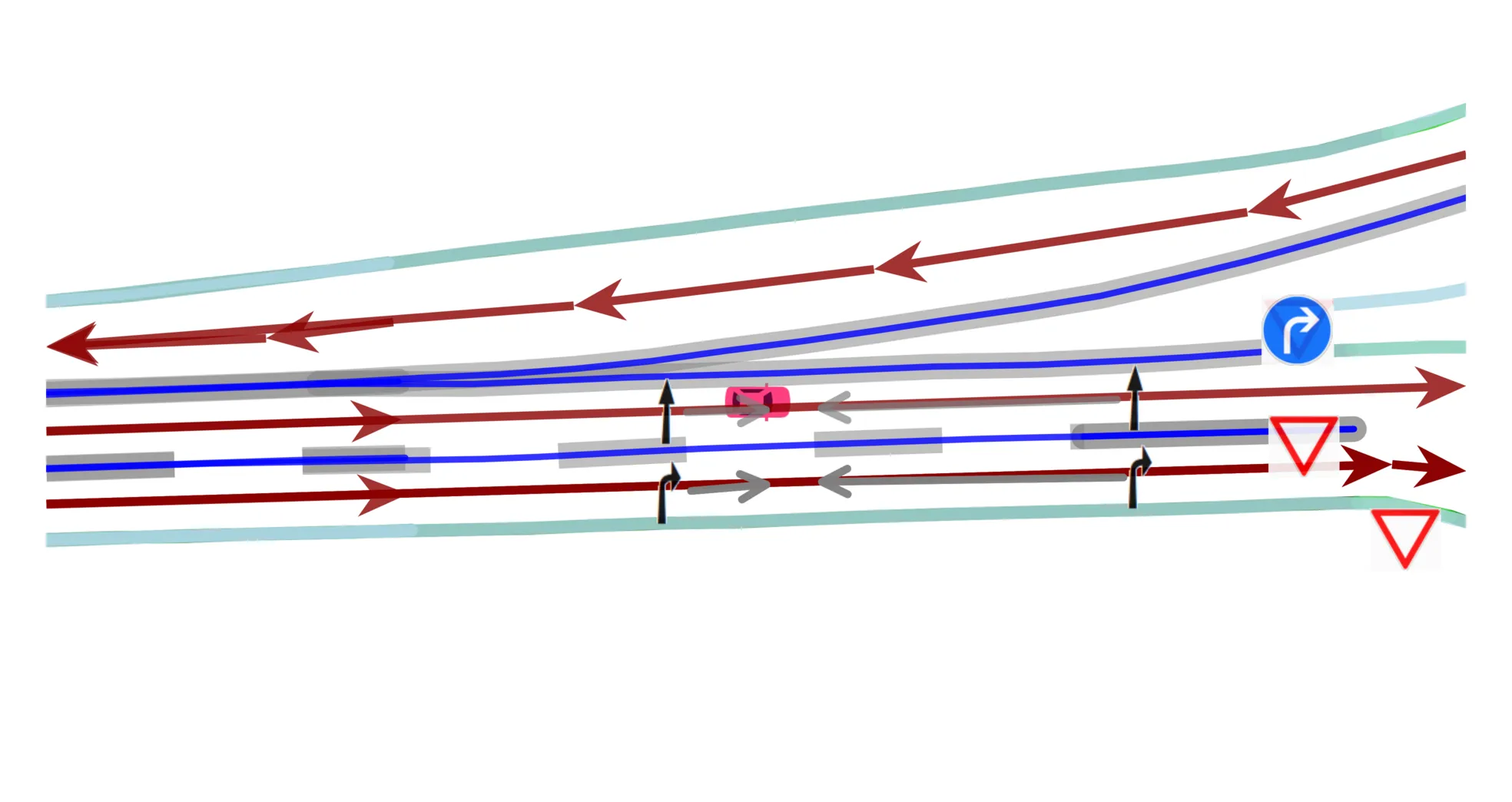
We provide fully relational 3D HD maps in Lanelet2 format alongside a bidirectional converter to the online HD map construction world (MapTRv2, MapQR, etc.). Jointly predicting full map topology with reprojection-accurate 3D element positions is an entirely new task.
View benchmark →With more than 400 m LiDAR range and a 16.2 MPix high-resolution camera, we can put monocular depth estimation to a new challenge. Comparing state-of-the-art methods, we found all methods to collapse to near-uniform predictions at long range.
View benchmark →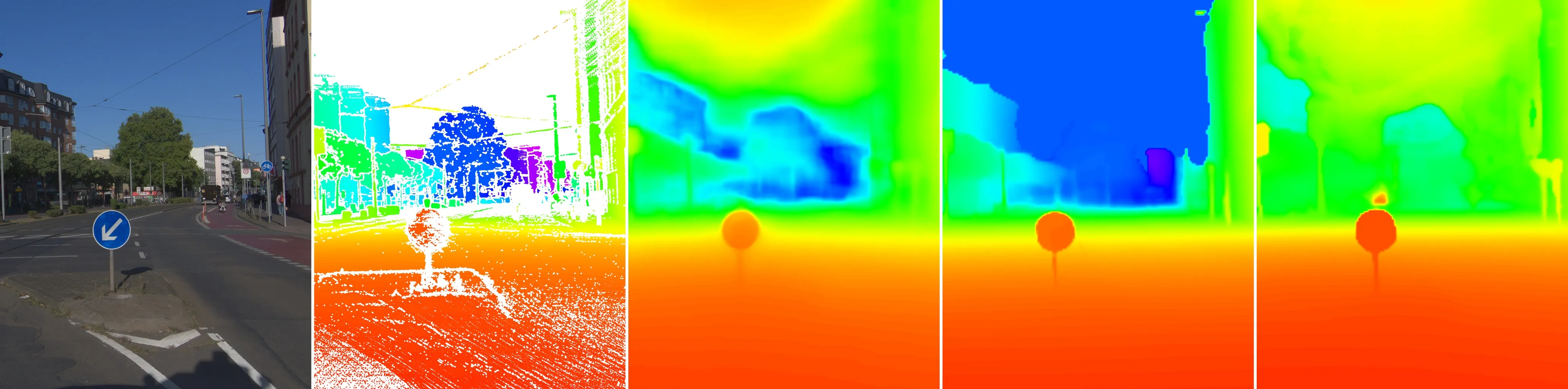
Left to right: input image, LiDAR ground truth, UniDAC, Depth Anything 3, MapAnything

Real frame (Δy = 0 m)

Rendered at Δy = +3 m
Hardware-synchronized global shutter cameras and high-fidelity image compression enable research on novel view synthesis (NVS). With reprojection-accurate 3D HD maps and LiDAR for visibility checking, we can offer an entirely new class of off-axis NVS benchmark: Traffic sign recall at lateral offsets up to ±3 m reveals geometric failures that current metrics (PSNR/SSIM/LPIPS) completely miss.
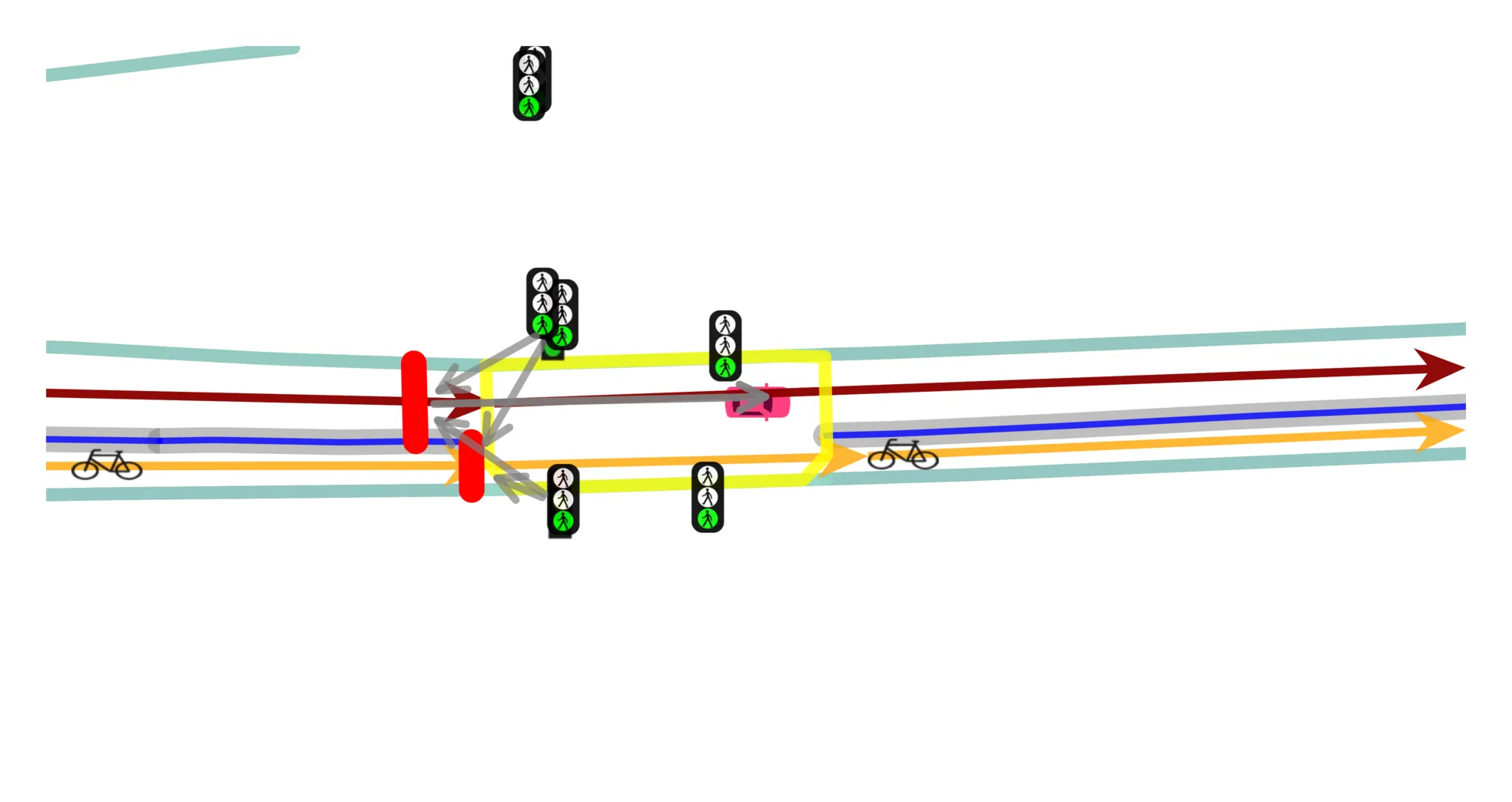
View benchmark →Production-grade HD maps combined with LiDAR and radar data enable E2E driving research beyond the camera-only paradigm. We evaluate models across three input tiers: single front-view camera, 360° surround cameras, and the full multimodal sensor suite.
View benchmark →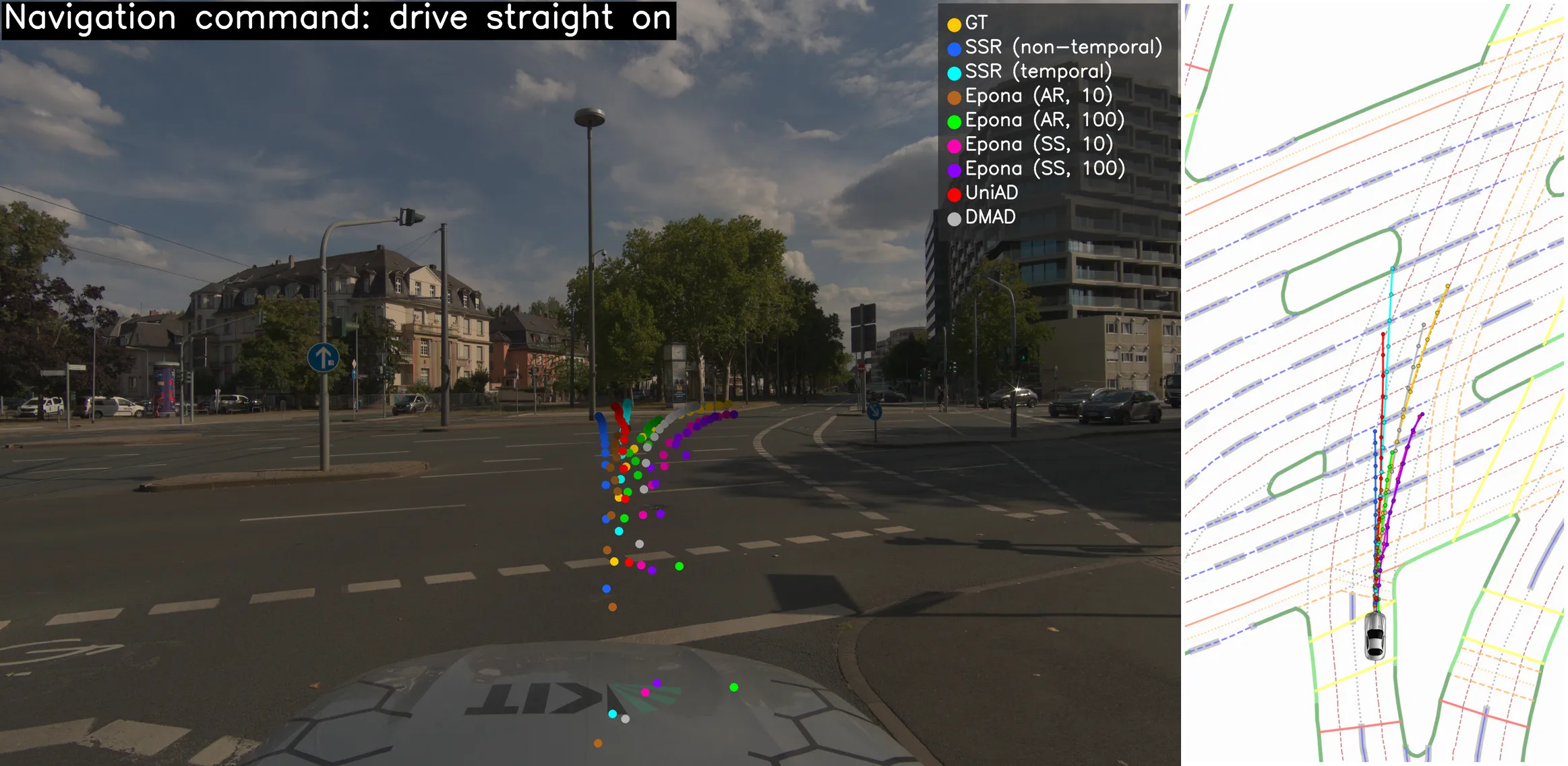

Trajectories from seven pretrained models illustrate the domain gap to nuScenes/nuPlan.
Citation will be added upon full release.
Check
HuggingFace
for updates.





















The HD maps required more than 10,000 hours of annotation and manual review. We sincerely thank all student research assistants and (former) colleagues who contributed to this effort but are not listed as authors.
The research leading to these results is partially funded by the German Federal Ministry for Economic Affairs and Energy within the project "NXT GEN AI METHODS". The authors gratefully acknowledge the computing time provided on the high-performance computer HoreKa by the National High-Performance Computing Center at KIT (NHR@KIT). This center is jointly supported by the Federal Ministry of Education and Research and the Ministry of Science, Research and the Arts of Baden-Württemberg, as part of the National High-Performance Computing (NHR) joint funding program. HoreKa is partly funded by the German Research Foundation (DFG).

 API
API